Перевод изображений с встроенным текстом: современные методы и практика
Оценочное время чтения: 8 минут
- Перевод изображений с текстом включает OCR, автоматический перевод и профессиональное наложение; современные решения обеспечивают более 95% точности для простых изображений.
- Культурная адаптация и корректная обработка измерений, символов и цветов критичны для маркетинга и технической документации.
- Автоматизация позволяет обрабатывать сотни и тысячи изображений за минуты, но при сложных диаграммах и специализированной терминологии необходим человеческий контроль.
- Инструменты для диаграмм и векторных файлов (SVG, CAD) облегчают замену текста и сохранение качества; CAD-чертежи требуют экспертизы.
Современные методы извлечения текста из изображений

Оптическое распознавание символов (OCR) стало основой для качественного перевода изображений. Современные OCR-системы научились работать с самыми разными форматами — от простых PNG до сложных многослойных диаграмм.
Оптическое распознавание символов

Технологии вроде Tesseract, ABBYY и интегрированные решения в Smartcat умеют автоматически определять язык текста, его ориентацию и даже сложное форматирование. Я помню, как еще пять лет назад приходилось вручную вводить каждую надпись с технических схем — сейчас это кажется дикостью.
Качество извлечения зависит от нескольких факторов: разрешение изображения, контрастность, используемый шрифт и язык. Особенно хорошо современные системы справляются с латинскими шрифтами и кириллицей, но могут испытывать трудности с рукописным текстом или стилизованными шрифтами.
Процесс извлечения
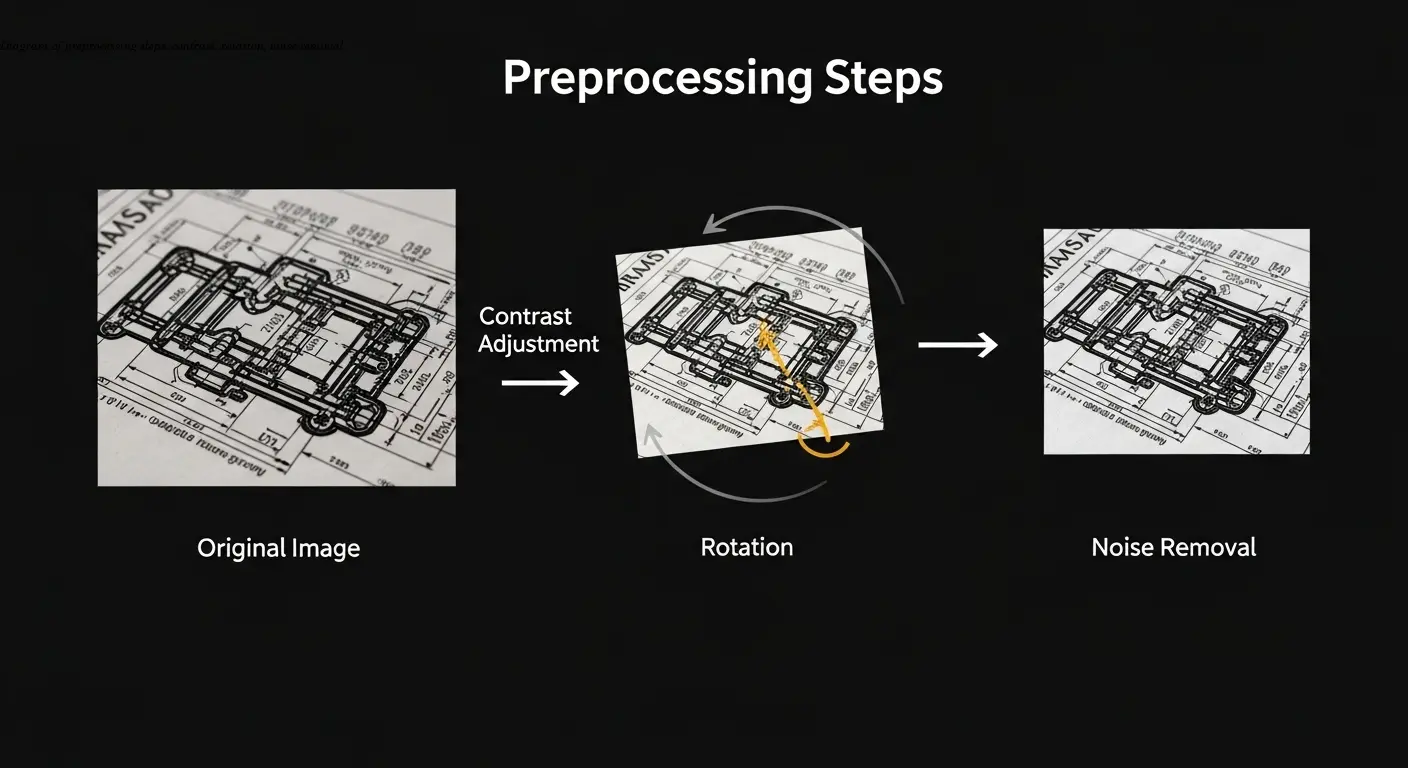
Процесс извлечения обычно включает предварительную обработку изображения — улучшение контраста, поворот для правильной ориентации текста, удаление шумов. Только после этого запускается собственно распознавание символов.
Новые AI-модели начинают понимать контекст изображения и подбирать оптимальные алгоритмы распознавания в зависимости от типа материала.
Технологии автоматического перевода встроенного текста
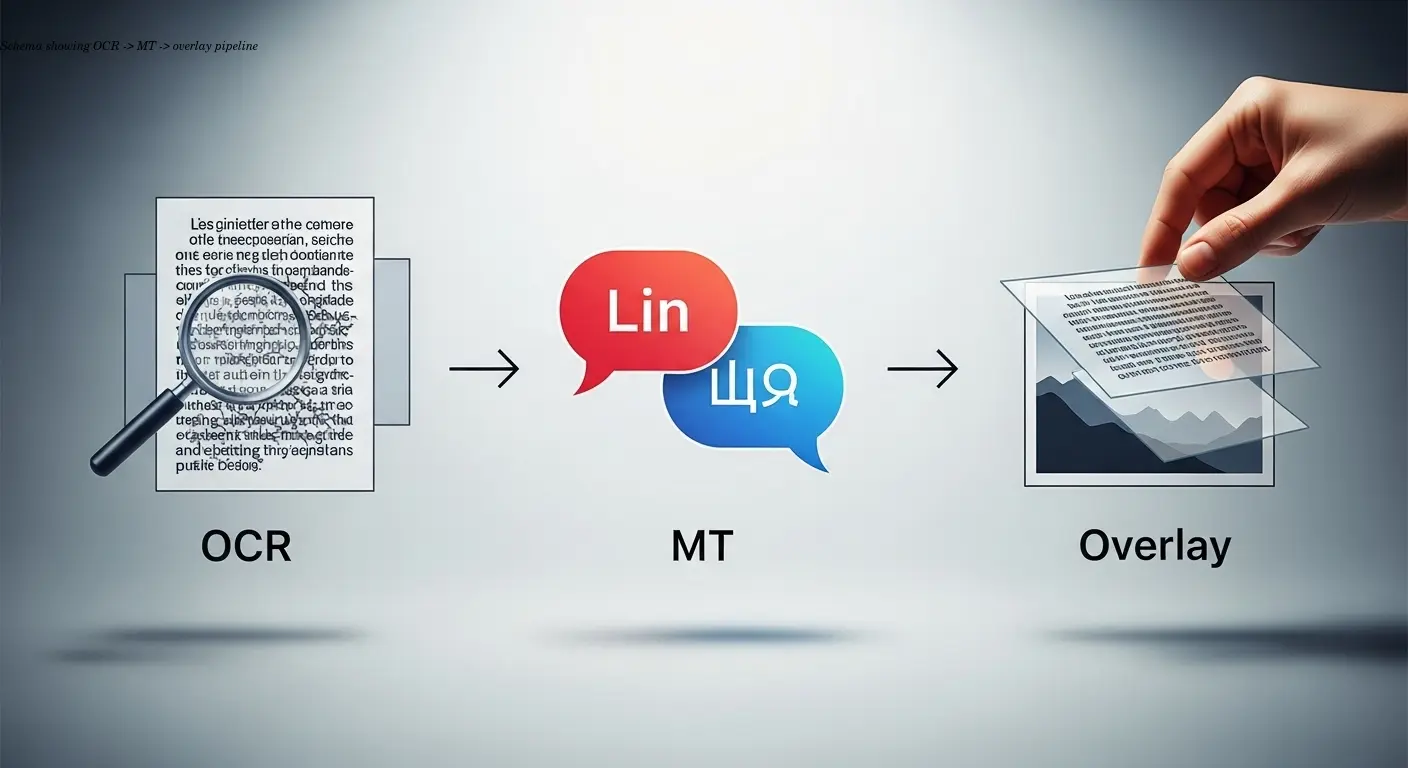
Перевод извлеченного текста требует особого подхода, поскольку работать приходится с короткими фрагментами, лишенными широкого контекста. Нейронные сети типа GPT и специализированные переводческие модели научились справляться с этой задачей довольно эффективно.
Основная сложность — текст на изображениях часто состоит из отдельных слов, аббревиатур или технических терминов. Система должна "угадать" контекст по минимальной информации. Например, слово Power может означать «мощность» в техническом контексте или «власть» в политическом.
Современные переводчики используют комбинированный подход: сначала анализируют тип изображения (техническая схема, интерфейс программы, рекламный материал), затем применяют соответствующие словари и модели перевода. Это значительно повышает качество результата.
Особое внимание уделяется переводу измерений, единиц, валют и других культурно-специфичных элементов. Система должна не только перевести текст, но и адаптировать его для целевой аудитории — например, перевести футы в метры или доллары в местную валюту.
Глоссарии и память переводов играют ключевую роль при работе с техническими материалами — они обеспечивают консистентность терминологии во всех переведенных изображениях проекта.
Создание качественных текстовых наложений

Наложение переведенного текста обратно на изображение — это искусство, требующее баланса между точностью перевода и визуальной привлекательностью. Простое размещение текста поверх оригинала часто выглядит неаккуратно и снижает восприятие материала.
Продвинутые системы анализируют оригинальное оформление: шрифт, размер, цвет, выравнивание, тени и другие эффекты, затем пытаются воссоздать эти параметры для переведенного текста. Это особенно важно для маркетинговых материалов, где визуальная составляющая критична.
Главная проблема — разная длина текста после перевода. Русский текст часто длиннее английского, что может нарушить композицию изображения. Умные системы автоматически подбирают размер шрифта или переносят текст на несколько строк.
В сложных случаях требуется ручная доработка. Особенно это касается инфографики, где текст тесно интегрирован с графическими элементами — здесь без дизайнера обойтись сложно.
Обеспечение читаемости и визуального баланса
Читаемость переведенного текста зависит от множества факторов: контраст, размер шрифта, тип и цвет. То, что хорошо читается на английском, может стать нечитаемым на русском из-за особенностей кириллицы.
Контроль контраста — первоочередная задача. Системы автоматически анализируют фон в месте размещения текста и подбирают цвет, обеспечивающий максимальную читаемость. Иногда добавляются тени, обводки или полупрозрачные подложки.
Выбор шрифта критичен для восприятия. Не все шрифты одинаково хорошо работают с кириллицей. Некоторые декоративные шрифты, прекрасно смотрящиеся на латинице, делают русский текст трудночитаемым.
Размещение текста требует понимания визуальной иерархии — переведенный текст должен находиться в логичном месте, не нарушая общую композицию изображения.
Культурная адаптация визуальных элементов

Локализация визуалов выходит далеко за рамки простого перевода текста. Разные культуры по-разному воспринимают цвета, символы и способы подачи информации.
Цветовая адаптация особенно важна для маркетинговых материалов. Красный в Китае ассоциируется с удачей, а в некоторых регионах — с опасностью. Белый в западных культурах символизирует чистоту, а в некоторых азиатских — траур.
Символы и иконография требуют особого внимания. Жест «окей» понятен американцам, но может оскорбить бразильцев. Изображения людей, животных, религиозных символов нужно адаптировать с учетом местных традиций и запретов.
Системы измерений — классический пример: футы, дюймы, фаренгейты и фунты нужно переводить в метры, сантиметры, цельсии и килограммы. Современные системы делают это автоматически, но требуют настройки для каждого региона.
Способы подачи информации тоже различаются: в некоторых культурах принято читать справа налево, что влияет на композицию диаграмм и инфографики.
Специализированные инструменты для перевода диаграмм
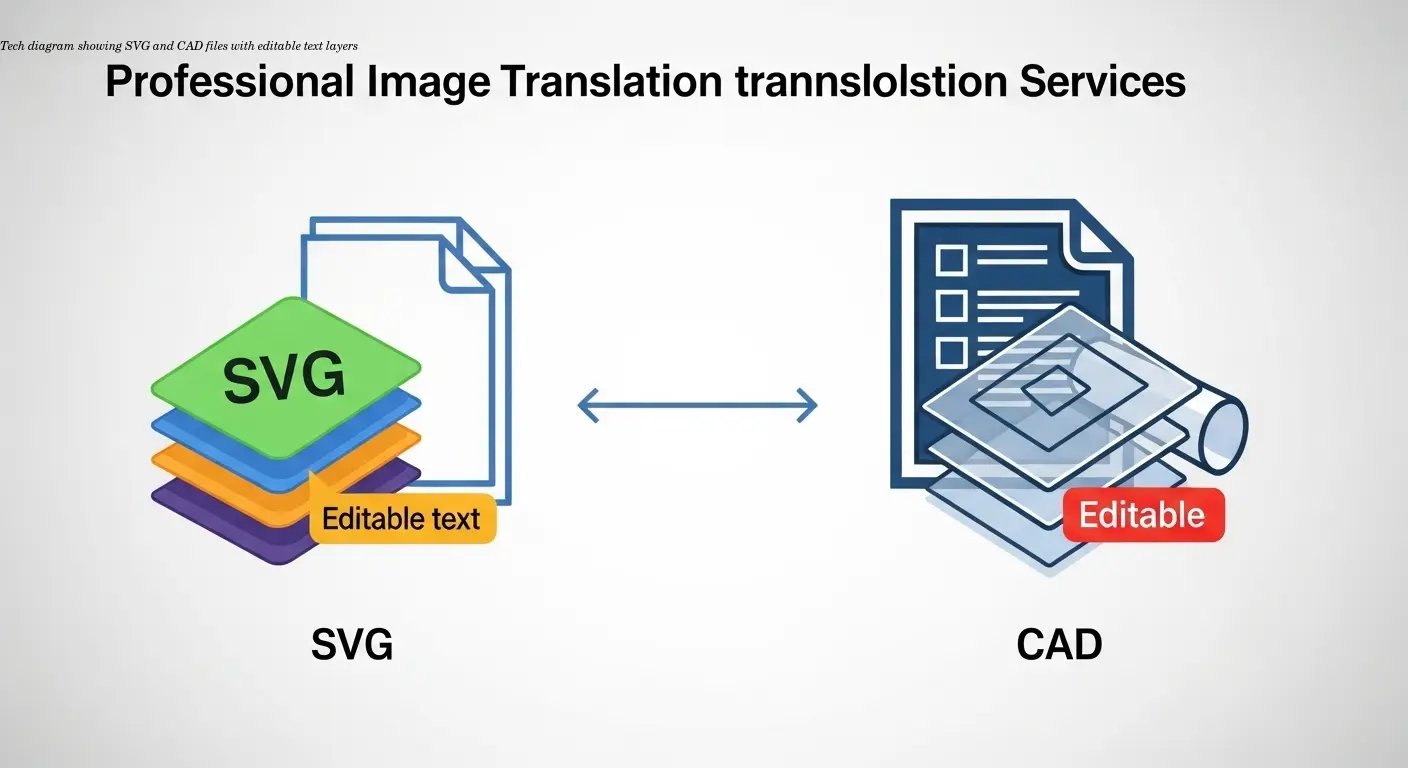
Перевод диаграмм и технических схем — одна из самых сложных задач. Здесь важна не только точность перевода, но и сохранение технической корректности и читаемости схемы.
Инструменты типа Smartcat заточены под работу с техническими материалами: они распознают структуру диаграмм, выделяют связанные элементы и сохраняют взаимосвязи между блоками схемы.
Векторные изображения поддаются автоматизации лучше растровых: в SVG текст остается редактируемым, что позволяет легко заменить его на переведенный, сохранив визуальные эффекты. CAD-чертежи требуют особого подхода и проверки техническими экспертами.
Интерактивные диаграммы усложняют локализацию — помимо перевода текста нужно адаптировать подсказки, анимации и логику взаимодействия.
Автоматизация процессов и контроль качества
Современная автоматизация позволяет обрабатывать тысячи изображений за час, но качество результата сильно зависит от настроек и подготовки материалов. Грамотно настроенная система экономит время и ресурсы.
Пакетная обработка эффективна для однотипных материалов — каталоги, технические руководства, серии инфографики. Система «запоминает» стиль и применяет одинаковые принципы ко всем изображениям серии.
Контроль качества остаётся критически важным. Даже самые продвинутые системы делают ошибки, особенно при сложных изображениях или специализированной терминологии. Человеческий контроль пока незаменим.
Интеграция с CAT-tools упрощает работу переводчика: извлеченный текст попадает в знакомую среду с глоссариями, памятью переводов и проверкой терминологии. После перевода текст автоматически возвращается в изображение.
Обратная связь помогает системам учиться: когда переводчик исправляет ошибки, система запоминает правки и учитывает их в будущих проектах — особенно важно для технических текстов.
FAQ
В: Насколько точен автоматический перевод изображений?
О: Точность современных систем достигает 95% для простых изображений с четким текстом. Для сложных диаграмм и стилизованных шрифтов точность может снижаться до 70-80%, поэтому требуется ручная проверка.
В: Можно ли переводить изображения с рукописным текстом?
О: Да, но качество сильно зависит от почерка. Печатные буквы распознаются лучше курсивных. Для важных документов рекомендуется ручная проверка результата.
В: Как долго занимает перевод одного изображения?
О: Автоматический процесс занимает от нескольких секунд до 2-3 минут в зависимости от сложности. Ручная проверка и доработка может потребовать дополнительно 10-30 минут.
В: Сохраняется ли качество изображения после перевода?
О: Современные системы стараются сохранить исходное разрешение и качество. При работе с векторными форматами качество не теряется совсем, с растровыми может быть небольшая деградация.
В: Какие форматы изображений поддерживаются?
О: Большинство систем работают с PNG, JPG, GIF, TIFF, BMP. Продвинутые инструменты поддерживают SVG, PDF, файлы Adobe Illustrator и другие векторные форматы.
В: Нужно ли знать исходный язык для перевода изображения?
О: Нет, современные системы автоматически определяют язык текста на изображении. Однако указание исходного языка может повысить точность распознавания.